Data Storage
As previously mentioned, MySQL was selected primarily because of the author’s familiarity with it, but also because it has evolved to handle many OLAP needs, at least on a small scale. For example, using the InnoDB storage engine allows for concurrent accesses and provides foreign-key support essential in data mining applications. For this application the initial entities consist of books, facts, and sellers (competitors) as shown in Figure 4.
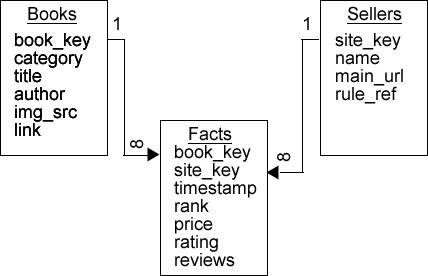
There are several things to consider with this simplistic design. First, because of Amazon’s enormity and the potential consequences of attempting to scrape on a large scale, initial decisions regarding the depth and breadth of the scrape were carefully considered. With respect to depth, the scrape was limited to the top 100 best-selling Kindle e-books in categories of interest to the developer with each category treated as a distinct scrape. Consequently, much of the desired metadata was not available in the front-end views being scraped (i.e. ISBN) and some of the uniqueness of the items were lost due to truncation (hidden overflow of titles) making it a challenge to avoid duplicating book records.
Second, although categories could (and maybe should) be treated as a distinct dimension or sub-dimension, in this case many books belonged to multiple categories. Rather than adding to the complexity, the decision was made to keep it simple meaning to only allow duplicate books if the category was also different. Lastly, while the facts entity captures the timestamp and the changing metrics (that do so every hour), a time dimension may be desirable to allow for rollups and drilldowns over more meaningful timeframes for trend analysis (e.g. week, month, etc).