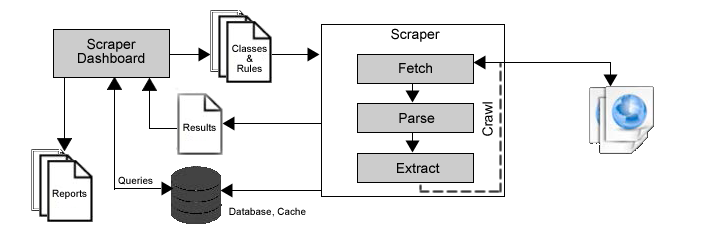
Architectural Framework
The initial goals of this scraper were for it to politely and accurately extract web content from specified URLs in accordance with the extraction rules, optimize runtime performance with the use of cache, insert parsed records into the database, output the results to the browser for inspection and debugging if needed, and allow for analytical reporting. PHP and the MySQL database were chosen as the main platform due to the author’s familiarity with them. A test server environment was established on the author’s personal machine consisting of the Windows version of the Apache, MySQL and PHP servers. Using a test environment minimized the risk of letting a potentially buggy application loose on the web.
A modular design was chosen to separate the core programming logic from the runtime logic and both from the presentation formatting and styling. Such a design is the easiest to maintain and troubleshoot. The main module named Xpath.php, instantiates the DOM Document and DOMXpath classes and runs the cURL command, the protocol for transferring URL information across the web.
The runtime module is named scraper.php which invokes the class module and includes the extraction rules. While the scraper instantiates the classes, it requires URLs to work. Separate modules contain the needed information and can be thought of as the frontier queue containing the URLs identified as scrapable according to the rules defined.