Data Extraction
The XPath class does the extraction using the rules established by the developer. For this application, the developer identified CSS selectors as the primary wrapper of the desired content. An extraction rule executes an XPath query that searches for the rule represented as a string expression. For example, Figure 3 shows a segment of Amazon’s best-selling Kindle e-books in programming.
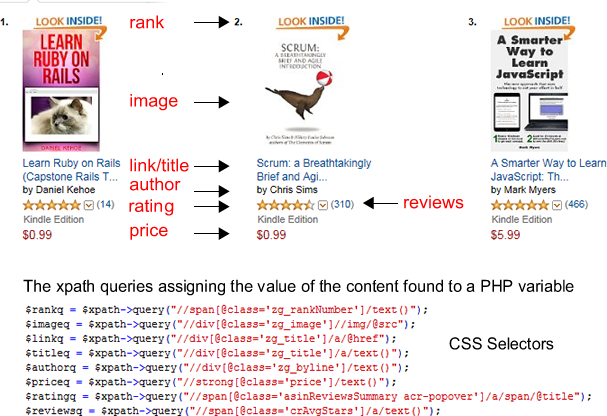
The above shows the power behind the XPath class in that when given a pattern to find in the URL, in this case, the CSS selectors, it ignores all other content and returns the value contained within the specified CSS wrappers. Currently the rules are “hard-coded” in the scraper that was made specifically for Amazon’s structured content. Ultimately, it would be desirable to store those patterns and pass them to a variable at runtime. Doing so would make the scraper adaptable to any site that has a similar structure but just uses different selector names.